The DOM
Table of Contents
In this post, I’ll be writing about how the browser represents a page using a DOM tree, the different types of nodes that you’ll find in the DOM tree, and selecting nodes to interact with in different ways.
Introduction
The Document Object Model (DOM) is a set of rules that browsers use to create a model of an HTML page in memory, and that JavaScript can use to access and update the contents of a web page while it is in the browser window. The DOM tree is the structure that the DOM uses to represent the page in memory. Each object in the tree represents a different part of the page. You can think of the DOM as an API that lets your script talk to the browser and ask it questions about the page, or tell it to update what is being shown to the user.
The DOM tree
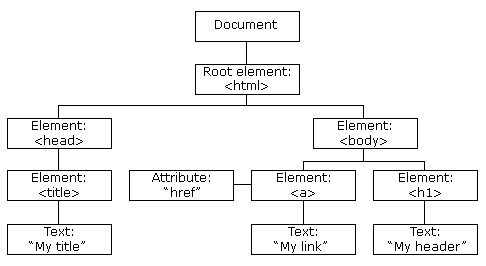
Every element in an HTML file is a node. At the very top and being the first element, there is the Document node. Under, the rest of the nodes that you can see like the HTML and body tag/element (from now on I will say element only) exists under. Each node has their own methods and properties, some are interchangeable. We can use these methods to change the DOM tree via scripts for updates. These changes are then rendered onto the page.
Node types
The first node is the document node, this node represents the entire page and it is an object as well that goes by the same name if you want to reference it. The second type is the element node. Elements like h1 - h6 that describe what parts are headings in a page and the p elements that guide as to what parts paragraphs of text start, etc. The third type are attribute nodes and are part of that element. Not children, sibling or otherwise. Sometimes we may need to change a characteristic of an element through one of it’s attributes with CSS for presentation purposes. The fourth type are text nodes, with this last node you can access the text between the element node as represented by the graph tree above.
Accessing and modifying the DOM tree
When making changes to the DOM’s elements there are several methods for doing so. Some are more common than others. Although all follow the rule of (1) finding the node that represents the element to work with and (2) Working with element nodes’ text content, child elements, and attributes to do something.
(1) Common ways to finding the node that represents the element to work with
The below methods allow you to select an individual element node:
- getElementById() - Searches for an element based on the value of it’s id attribute (single value, unique within a page).
- querySelector() - Searches for an element using a CSS selector and returns the first matching element.
These methods allow you to select multiple elements, we call these nodelists:
- getElementsByClassName - Searches for all elements with a given class name attribute.
- getElementsByTagName - Searches for all elements with a given specified tag name.
- querySelectorAll - Searches for all elements using a CSS selector.
These methods allow you to traverse between different related nodes:
- parentNode - Returns the parent node of an element (single value returned).
- firstChild/ lastChild - Returns the first child / last child node of the current element.
- previousSibling / nextSibling - Returns the previous / next node at the same level as an element in the DOM tree.
(2) Working with element nodes’ text content, child elements, and attributes
To access / update text nodes we can use the following properties:
- nodeValue - Represents the text content of an element (only used with text nodes, does not work with text inside any child elements).
To work with HTML content:
textContent - Represents the text content of an element (used with text nodes and element nodes).
innerHTML - Represents the HTML content of an element and allows for access to child elements and text content. (innerHTML is not safe due to XSS attacks vulnerabilities).
There are methods to create, add, and remove nodes to a tree (DOM manipulation):
createElement() - Creates a new element node.
createTextNode() - Creates a new text node.
appendChild() - Adds a new node to the end of a given element as a child node.
removeChild() - Removes a given child node from an element.
To access or update HTML values we can use the following properties / methods:
className / id - Represents the value of the class / id attribute.
setAttribute() / removeAttribute() - Allows you to set / remove the value of an attribute on an element.
hasAttribute() - Checks if an element has a certain attribute.
getAttribute() - Returns the value of an attribute on an element.
children - Represents the child nodes of an element.
attributes - Represents the attribute nodes of an element.
getAttribute() - Returns the value of a specified attribute of an element.
setAttribute() - Sets the value of a specified attribute of an element.
hasAttribute() - Checks if an element has a specified attribute.
removeAttribute() - Removes a specified attribute from an element.
Caching DOM queries concept
Caching a query is a technique used by developers to reduce the number of times a query is executed and to improve performance. The idea is to store the result of a query in a variable so that the query does not need to be run again to lookup an element node. In the example below, we are querying for an element with the id of main and storing the result in a variable called main. We can then use the main variable to access the element, instead of querying for it each time we want to use it.
main.textContent = 'This is the new text content.'
Ending Thoughts
In this post, we’ve gone over how the browser represents a page using a DOM tree, the different types of nodes that you’ll find in the DOM tree, and selecting nodes to interact with in different ways. We’ve also looked at how to access and modify the DOM tree, and how to cache DOM queries to improve performance. I hope this post has been helpful in understanding how the DOM works and how to use it to manipulate the contents of a web page.